AI Megathread
-
@Pavel said in AI Megathread:
I’ve started using semicolons more in my notes:
Until some article points out that semicolons also occur more often in AI-generated work than in the average (non-professional) writing, and you’re right back where you’ve started. I’m honestly surprised it isn’t mentioned in the wikipedia article, since I’ve seen it highlighted elsewhere.
@Trashcan said in AI Megathread:
These tools are aware of the negative ramifications of a false positive and are biased towards not returning them.
And yet they still do, and not necessarily at the 1% false-positive rate they claim. For example, from the Univ of San Diego Legal Research Center:
Recent studies also indicate that neurodivergent students (autism, ADHD, dyslexia, etc…) and students for whom English is a second language are flagged by AI detection tools at higher rates than native English speakers due to reliance on repeated phrases, terms, and words.
This has been widely reported elsewhere too. It’s a real concern and it has real-world implications on peoples’ lives when they are falsely accused of cheating/etc.
-
@Faraday said in AI Megathread:
For example, from the Univ of San Diego Legal Research Center:
If we’re getting down to the level of sample size and methodology, it’s probably worth mentioning that this study looked at 88 essays and ‘recent’ in this context was May 2023, or 6 months after the release of ChatGPT. It is safe to assume the technology has progressed.
-
@Trashcan It is good to examine the robustness of the particular studies referenced in that article (some of which were from 2023, not 2024, though), but I’ve seen no evidence that the tech on the whole has gotten any better in this particular regard.
-
@Faraday ok but 88 essays is not a sample size that anyone can take seriously.
-
@hellfrog I’m not really sure what study you’re talking about that specifically had the 88 essays. The Univ of San Diego site I linked to had a whole bunch of studies referenced, and I cited their overall conclusions. I am also drawing from reporting I’ve read in other media sources, but which I don’t have immediately handy.
-
@Faraday said in AI Megathread:
Until some article points out that semicolons also occur more often in AI-generated work than in the average (non-professional) writing, and you’re right back where you’ve started.
I don’t like this game anymore.
-
I’ve got this AI detector thing and I hate it with the hatey black hate sauce.
No, you stupid thing, 100% of this student’s paper isn’t likely to be AI, I’ve watched him building this argument for twelve weeks.
Say, what, this one’s paper is also likely all AI? Who the heck tells AI to do APA formating so creatively wrongly?
Yeah, right, this is so likely all AI, the student fed the assignment into AI along with the instructions, “Write this in the style of someone who doesn’t know how to write an academic paper trying to write an academic paper.”
I really hope other instructors are not taking this daft thing seriously.
-
@Gashlycrumb
That does sound frustrating, and while I’ve been in defense of the odds of AI detectors not falsely accusing people throughout this thread, it’s still worth noting that even recent studies find wide disparities between product offerings. From one of the studies already linked:
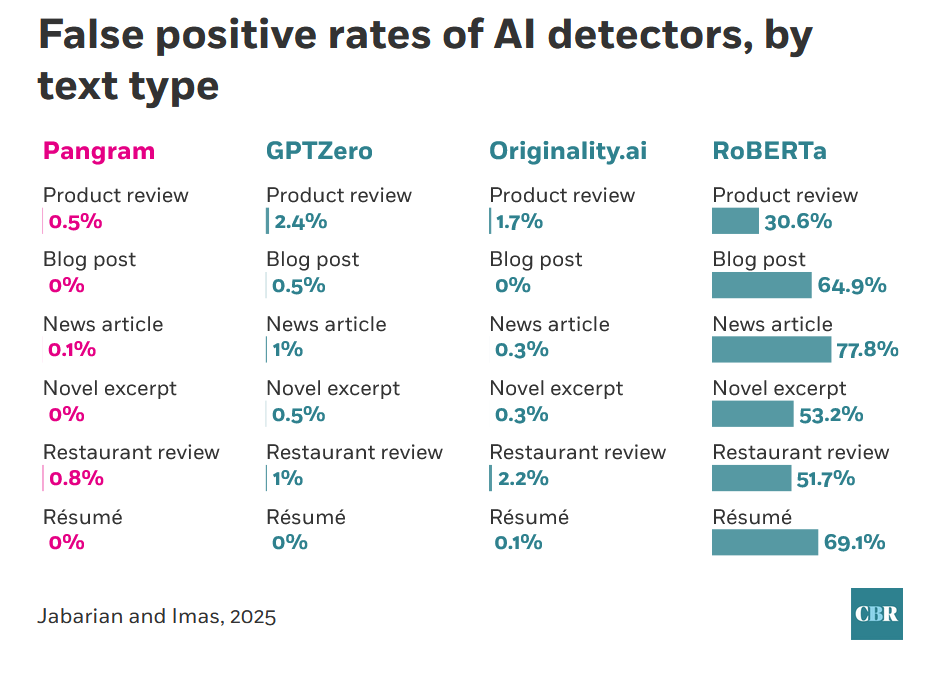
Clearly RoBERTa, the open-source offering, is not something anyone should be using. I hope there’s some sort of feedback mechanism to the administration that the particular tool they’ve selected is highly unsuited to the task.
he/him
this machine kills fascists -
@Trashcan I don’t know where essays fit into that chart, but let’s pretend for the sake of argument it’s on par with the GPTZero news articles at 1% false positive rate. With millions of students writing millions of essays, that’s still hundreds of thousands of people falsely being accused of cheating, with potentially ruinous consequences. That’s just not acceptable IMHO.
-
@Faraday
There was cheating before AI and there were false accusations of cheating before AI detectors. Being falsely accused of using AI is no more serious than being accused of plagiarism.What is the alternative?
-
@Trashcan I think you’re underestimating the psychological effect that takes place when people trust in tools. There’s a big difference between “I think this student may have cheated” and “This tool is telling me this student cheated” when laypeople don’t understand the limitations of the tool.
I’ve studied human factors design, and there’s something that happens with peoples’ mindsets once a computer gets involved. We see this all the time - whether it’s reliance on facial recognition in criminal applications, self-driving cars, automated medical algorithms, etc.
Also, plagiarism detectors are less impactful because they can point to a source and the teacher can do a human review to determine whether they think it’s too closely copied. That doesn’t work for AI detection. It’s all based on vibes, which can disproportionately impact minority populations (like neurodivergent and ESL students). I also highly doubt that hundreds of thousands of students are falsely accused of plagiarism each year, but I can’t prove it.
As for the alternative? I don’t think there is one single silver bullet. IMHO we need structural change.
-
Just to summarize, and please correct me, Trashcan thinks that SOME amount of false positives (1%) using tools is acceptable in the fight against AI and Faraday thinks that ZERO amount of false positives using tools is acceptable in the fight against AI? Am I understanding that you think its better to trust your gut here, Faraday?
-
@Faraday said in AI Megathread:
IMHO we need structural change.
Agreed. It’s fundamentally not even really an “AI” problem at its core, but a sort of “humans relying on authorities instead of thinking” problem.
-
@Yam That isn’t exactly what I said. It’s a complex issue requiring multiple lines of defense, better education, and structural change. But I am saying that even 99% accuracy is too low.
For example, say you have a self-driving car. Are you OK if it gets into an accident 1 out of every 100 times you drive it?
Say you have a facial recognition program that law enforcement leans heavily on. Are you OK if it mis-identifies 1 out of every 100 suspects?
I’m not.
1% failure doesn’t sound like much until you multiply it across millions of cases.
-
@Yam
I think that some amount of mistakes in any system are acceptable. Nothing is flawless. To me the barrier that a system needs to clear is “better than any alternative”.In AI detectors, we’ve already seen that most of the time, people unassisted get it right only 50-60% of the time. Certain detectors are performing at level where less than 1% of results are false positive. That seems better.
@Faraday said in AI Megathread:
say you have a self-driving car. Are you OK if it gets into an accident 1 out of every 100 times you drive it?
There were about 6 million auto accidents in 2022. If the self-driving car (extrapolated to the whole population) would have caused 5 million accidents, it would be better.
@Faraday said in AI Megathread:
Say you have a facial recognition program that law enforcement leans heavily on. Are you OK if it mis-identifies 1 out of every 100 suspects?
If this facial recognition program does a better job than humans, yes I am okay with it. Humans are notoriously poor eye witnesses.
Eyewitness misidentification has been a leading cause of wrongful convictions across the United States. It has played a role in 70% of the more than 375 wrongful convictions overturned by DNA evidence. In Indiana, 36% of wrongful convictions have involved mistaken eyewitness identification.
@Pavel said in AI Megathread:
but a sort of “humans relying on authorities instead of thinking” problem
There are cases when humans should rely on authorities instead of thinking. No one is advocating for completely disconnecting your brain while making any judgment, but authoritative sources can and should play a key role in decision-making.
he/him
this machine kills fascists -
@Trashcan said in AI Megathread:
There were about 6 million auto accidents in 2022. If the self-driving car (extrapolated to the whole population) would have caused 5 million accidents, it would be better.
Lol man, I have to agree. I realize that we’re generally anti-generative AI in art/writing here but I’ll be honest, if the computer drives the car better than my anxious ass, I’ll ride along.
-
@Trashcan said in AI Megathread:
There were about 6 million auto accidents in 2022. If the self-driving car (extrapolated to the whole population) would have caused 5 million accidents, it would be better.
Making cities walkable would be far better than throwing more money into the abyss that cities become when they’re overrun by self-driving cars.
Game-runner of Silent Heaven, a small-town horror MU.
https://silentheaven.org -
@Yam said in AI Megathread:
if the computer drives the car better than my anxious ass, I’ll ride along.
That’s a big “if” though, and is the crux of my argument.
@Trashcan said in AI Megathread:
If this facial recognition program does a better job than humans, yes I am okay with it. Humans are notoriously poor eye witnesses.
The difference is that many people know that humans are notoriously poor eye witnesses. Many people trust machines more than they trust other humans, even when said machines are actually worse than the humans they’re replacing. That’s the psychological effect I’m referring to.
-
@Jumpscare said in AI Megathread:
@Trashcan said in AI Megathread:
There were about 6 million auto accidents in 2022. If the self-driving car (extrapolated to the whole population) would have caused 5 million accidents, it would be better.
Making cities walkable would be far better than throwing more money into the abyss that cities become when they’re overrun by self-driving cars.
Unfortunately, tech bros would rather reinvent bandaid solutions over and over again instead of actually working to improving the future.
-
@Jumpscare Walkable cities is a whole 'nother can of worms.